

Creating powerful AI applications with years of expertise
We understand that Large Language Models (LLMs) are more than just chatbots: they are engines of business logic. Our team possesses the deep technical experience necessary to architect, fine-tune, and deploy sophisticated AI models that solve real-world problems. From startups to enterprises, clients trust Lexogrine to navigate the complexities of AI, ensuring solutions are scalable, secure, and precisely tailored to their operational needs.
About LLM: the engine of modern intelligence
Large Language Models (LLMs) are advanced neural networks trained on vast datasets to understand, generate, and interpret human language and code with unprecedented fluency. These models are the backbone of Generative AI, capable of reasoning, summarizing complex data, and automating creative tasks.
However, unlocking their true potential requires architectural mastery. Lexogrine excels where standard implementations fall short. Our deep expertise allows us to fine-tune accuracy, optimize latency, and build robust guardrails, transforming raw AI potential into precise, enterprise-grade solutions that drive real business value.



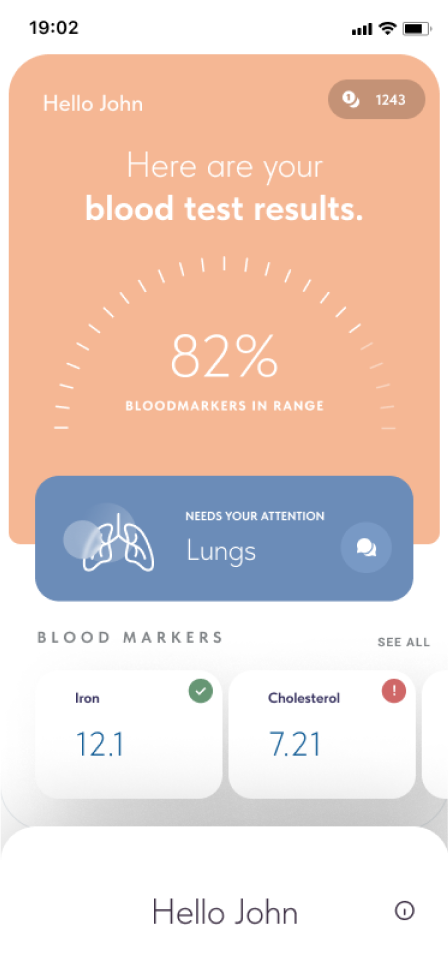

Mysti AI - LLM-powered expert in your pocket
Mysti AI is a top-notch solution that successfully utilizes AI and frontier LLM models to gather your health testing results in one place and review them using the full power of advanced Generative AI. With the right mixture of powerful external models and dedicated, custom AI solutions, Mysti AI is a perfect application for the AI-powered future of healthcare.
The quality of Lexogrine's work and approach to the project genuinely exceeded my expectations.


Our Core LLM Development Services
As an LLM development company, we offer a full spectrum of services designed to leverage the power of language models.
Generative AI Application Development
We transform raw AI capabilities into user-friendly applications. As a Generative AI development partner, we build end-to-end platforms that generate text, code, images, or insights. This includes intelligent assistants, automated content generators, and dynamic workflow automation tools.
LLM Integration & API Orchestration
We seamlessly integrate powerful third-party APIs (OpenAI, Anthropic, Gemini) into your existing ecosystem. Our team handles the complex orchestration of prompts, context management, and output parsing to ensure your legacy systems gain modern AI capabilities without a complete rewrite.
Custom LLM Development & Fine-Tuning
One size does not fit all. We specialize in developing custom LLM solutions tailored to your specific industry data. Whether you need to fine-tune open-source models (like Llama, Mistral, or Qwen) or build a proprietary engine, we ensure the model speaks your business language fluently.
RAG (Retrieval-Augmented Generation) Systems
Hallucinations are the enemy of enterprise AI. We implement advanced RAG architectures that connect LLMs to your live, proprietary data sources. This ensures that the AI's responses are grounded in fact, up-to-date, and verifiable.

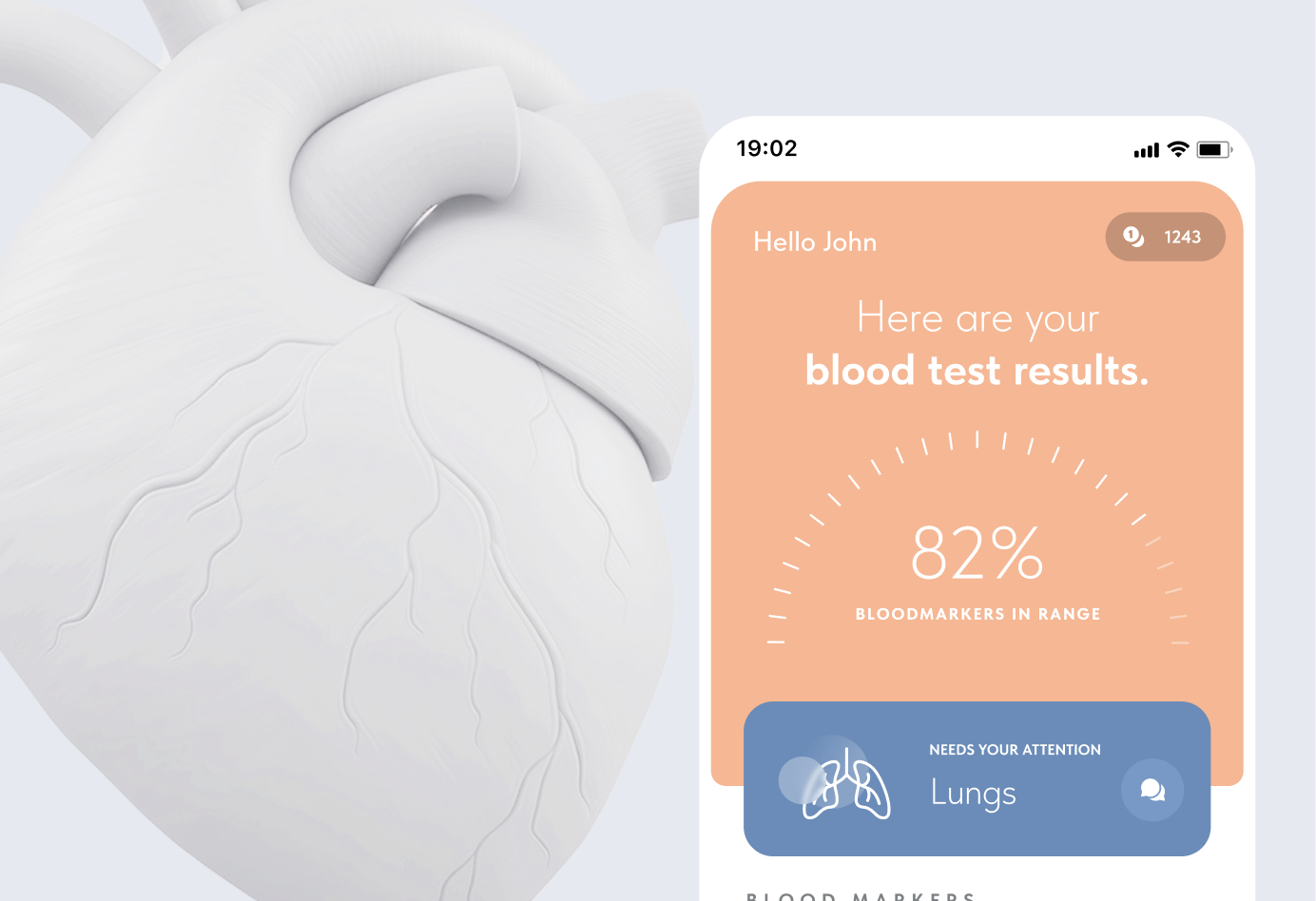
Technology stack: powering next-gen AI
To offer top-tier services as an LLM development company, we utilize the most robust and efficient technologies in the AI landscape.
Frontier models: OpenAI, Google Gemini, Anthropic Claude
As the gold standard in Generative AI, we leverage the full capabilities of the OpenAI, Google, and Anthropic ecosystems. Our expertise includes optimizing token usage, prompt engineering, and utilizing solutions like the Assistants API to build highly capable, conversational interfaces.
LangChain
LangChain is the industry standard for building context-aware reasoning applications. We use it to chain together multiple components, allowing LLMs to interact with other data sources and environments. It is essential for creating complex agents that can "think" and act.
LlamaIndex (GPT Index)
Data is the fuel for AI. We utilize LlamaIndex to connect your custom data (PDFs, SQL, Notion, APIs) to LLMs. It is the backbone of our RAG solutions, ensuring high-performance data indexing and retrieval for accurate query responses.
Hugging Face
For clients requiring open-source flexibility and on-premise privacy, we utilize the Hugging Face hub. It allows us to access, deploy, and fine-tune thousands of state-of-the-art models (like BERT, Falcon, or Bloom) specific to your niche requirements.
Pinecone & Vector Databases
Long-term memory is critical for AI. We implement vector databases like Pinecone, Weaviate, or Milvus to store data embeddings. This allows the LLM to recall vast amounts of information instantly, enabling semantic search and context retention over long conversations.
The Lexogrine Synergy: combining LLMs with modern tech
Merely having an AI model isn't enough - it must live within a robust application. Lexogrine stands out by fusing LLM development with our proven expertise in web and cloud technologies.
LLM + Node.js
Node.js is perfect for the event-driven nature of AI. We use Node.js to build scalable backends that handle real-time AI streams. Its non-blocking I/O is ideal for managing long-running LLM requests while keeping the application responsive for thousands of concurrent users.
LLM + React
The frontend is where the user meets the AI. We build dynamic React interfaces that support streaming text responses (typing effects), interactive data visualization based on AI output, and intuitive chat UIs. We ensure the UX manages the unpredictability of generative content gracefully.
LLM + React Native
We bring intelligence to mobile. By integrating lightweight models or API endpoints into React Native, we create mobile apps that offer on-the-go AI assistance. We optimize for latency and battery life, ensuring a smooth "AI in your pocket" experience.
LLM + AWS & Cloud Services
Scalability is non-negotiable. We deploy AI solutions on AWS, utilizing services like Amazon Bedrock for accessing foundation models and SageMaker for training. We architect serverless environments (Lambda) to handle spikes in AI traffic, ensuring cost-efficiency and enterprise-grade security.
FAQ - Frequently Asked Questions about LLM Development
What is the difference between custom LLM development and using ChatGPT?
Using ChatGPT gives you a generalist assistant. As an LLM development company, Lexogrine builds solutions that are integrated directly into your workflows, trained on your specific data, and secured within your infrastructure, offering capabilities a public chatbot cannot provide.
Can you integrate AI into my existing software?
Absolutely. Our background in Node.js and React allows us to inject AI features. such as smart search, automated reporting, or chatbots, directly into your legacy or current applications without rebuilding them from scratch.
How long does it take to build a Generative AI MVP?
Timelines vary based on complexity, but with our expertise in frameworks like LangChain, we can often deliver a functional Proof of Concept (PoC) or MVP in as little as 4–8 weeks.
Is my data safe when using LLMs?
Yes. We prioritize security. We can implement local open-source models that never send data to external APIs, or use enterprise-grade cloud environments (like Azure OpenAI or AWS Bedrock) that guarantee your data is not used to train public models.
Voices of trust and satisfaction

5.0

The quality of Lexogrine's work and approach to the project genuinely exceeded my expectations.
Lexogrine was even able to add features and improve the platform’s speed in a mere week!

Every question and request was accommodated quickly and with ease by Lexogrine.
