What Is AI Scraping? How Businesses Use AI for Smarter Web Data Extraction
What is AI scraping?
AI scraping is web data extraction that uses machine learning or language models to identify, classify, normalize, and map website content into a requested schema. It helps when layouts differ, labels vary, or facts sit inside prose, tables, PDFs, images, or JavaScript-rendered screens.
It does not replace standard scraping. A stable price element is cheaper and faster to parse with a CSS selector. AI helps when meaning matters, not only HTML position. The term is an umbrella label, not a formal web standard.
Before using any scraping workflow, teams should confirm that the source, access method, purpose, storage, and reuse of the data are permitted. The examples in this article assume lawful access, respect for source policies, and appropriate review of privacy, copyright, contractual, security, and competition-law constraints.
AI scraping vs traditional web scraping
Traditional scraping relies on APIs, HTML parsers, CSS selectors, XPath, regular expressions, and fixed rules. AI scraping adds semantic extraction, classification, and flexible schema mapping.
Web crawling finds URLs. Scraping extracts fields. Browser automation performs actions on rendered pages. Extraction APIs package fetching and parsing. RPA repeats fixed screen steps, while people handle manual collection. AI can support each method without replacing its role.
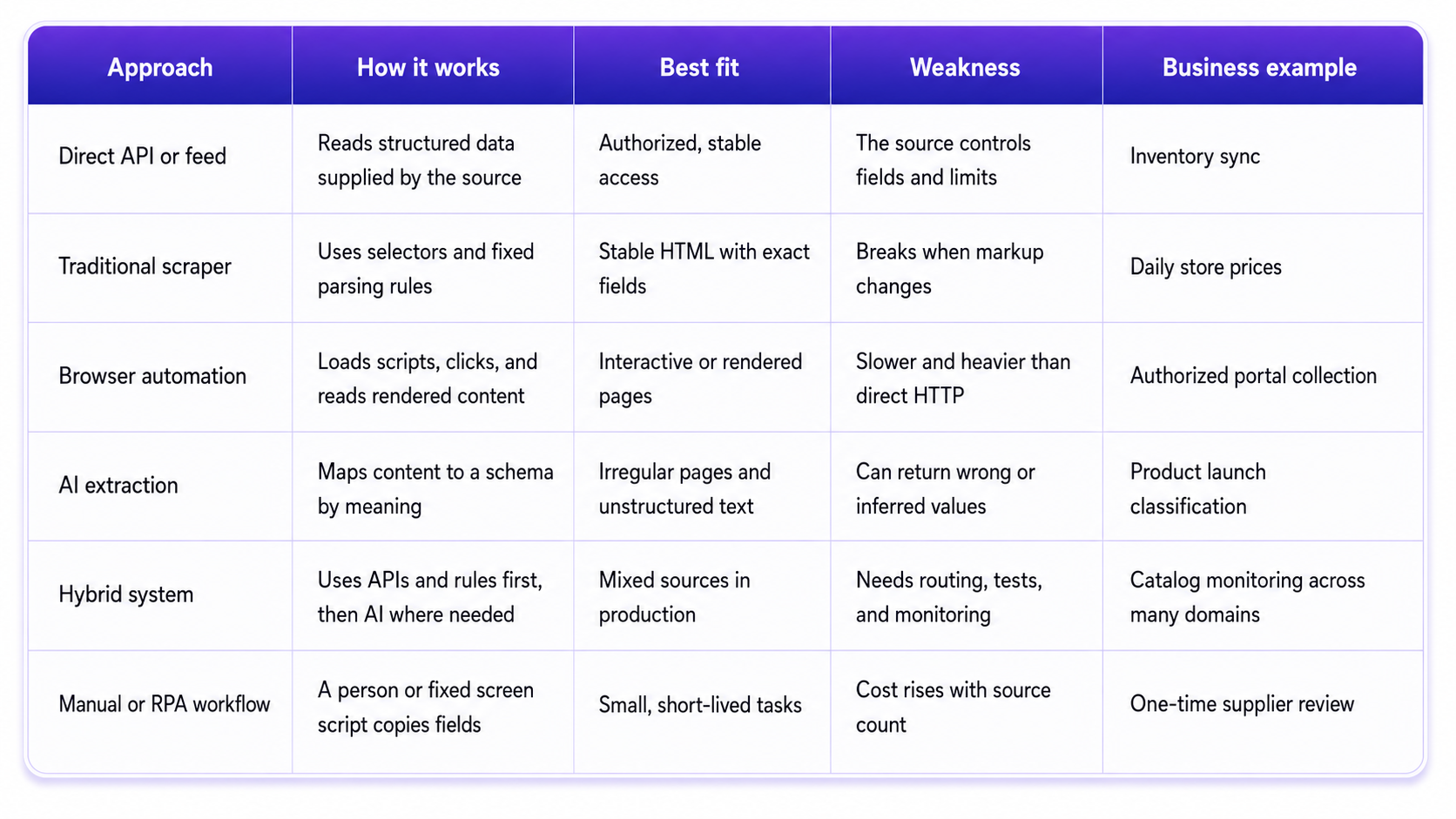
Most production systems use a hybrid path: rules collect exact facts, browsers handle rendered flows, AI interprets messy content, and validation checks results.
Why businesses use AI for web data extraction
Businesses rarely need raw HTML. They need records, alerts, comparisons, and source evidence that other software can use.
Here is why AI can help:
- Faster research across differently structured sources
- Better coverage of pages that would need separate parsers
- Less manual review when confidence rules work well
- Consistent fields from prose, tables, and mixed labels
- Better monitoring of products, listings, reviews, and market changes
- Faster transfer of fresh web content into CRM, search, reporting, or agent workflows
The goal is trusted business data tied to a defined use.
How AI scraping works
A production workflow often follows these steps:
- Source discovery: Define approved URLs, sitemaps, feeds, or search queries.
- Crawling or browser automation: Use direct HTTP first. Open a browser when rendering or permitted interaction is required.
- Page rendering: Wait only for the content needed by the job.
- Content cleaning: Remove menus and repeated blocks, then keep a snapshot or content hash.
- AI extraction: Identify entities, events, attributes, topics, or relationships.
- Schema mapping: Return named fields with types, allowed values, and null rules.
- Validation: Check formats, ranges, cross-field logic, and source evidence.
- Deduplication: Match records that refer to the same product, company, property, job, or event.
- Storage: Save the record, source URL, fetch time, model version, and evidence span.
- Monitoring and review: Track failures, coverage, confidence, freshness, and cost. Route uncertain or sensitive records to people.
URL -> fetch or render -> cleaned content -> rules and AI -> schema validation -> deduplication -> database -> API, dashboard, or alert
Let’s break it down by model type. Language models can map prose into JSON. Classifiers can tag page type or event. Embeddings can match similar records. Computer vision and OCR can read scans or image-heavy pages. Rule-based parsers remain better for exact IDs, prices, dates, and stable markup.
What AI adds to web data extraction
AI is useful when extraction depends on meaning. It can handle:
- Entity extraction and category classification
- Product attribute mapping across inconsistent labels
- Review sentiment and topic extraction
- Layout and table interpretation
- Summaries and meaningful change detection
- Record matching, deduplication, and normalization
- Natural-language instructions mapped to a formal schema
Limits matter. A model can misread text, place a value in the wrong field, or infer a value that never appeared. Schema-constrained output checks shape, not truth. Teams still need evidence, null handling, validation, and review thresholds.
Cost grows with browser use, page length, tokens, and retries. Stable pages at high volume belong on deterministic parsers. Route only semantic or irregular work to AI.
Common business use cases
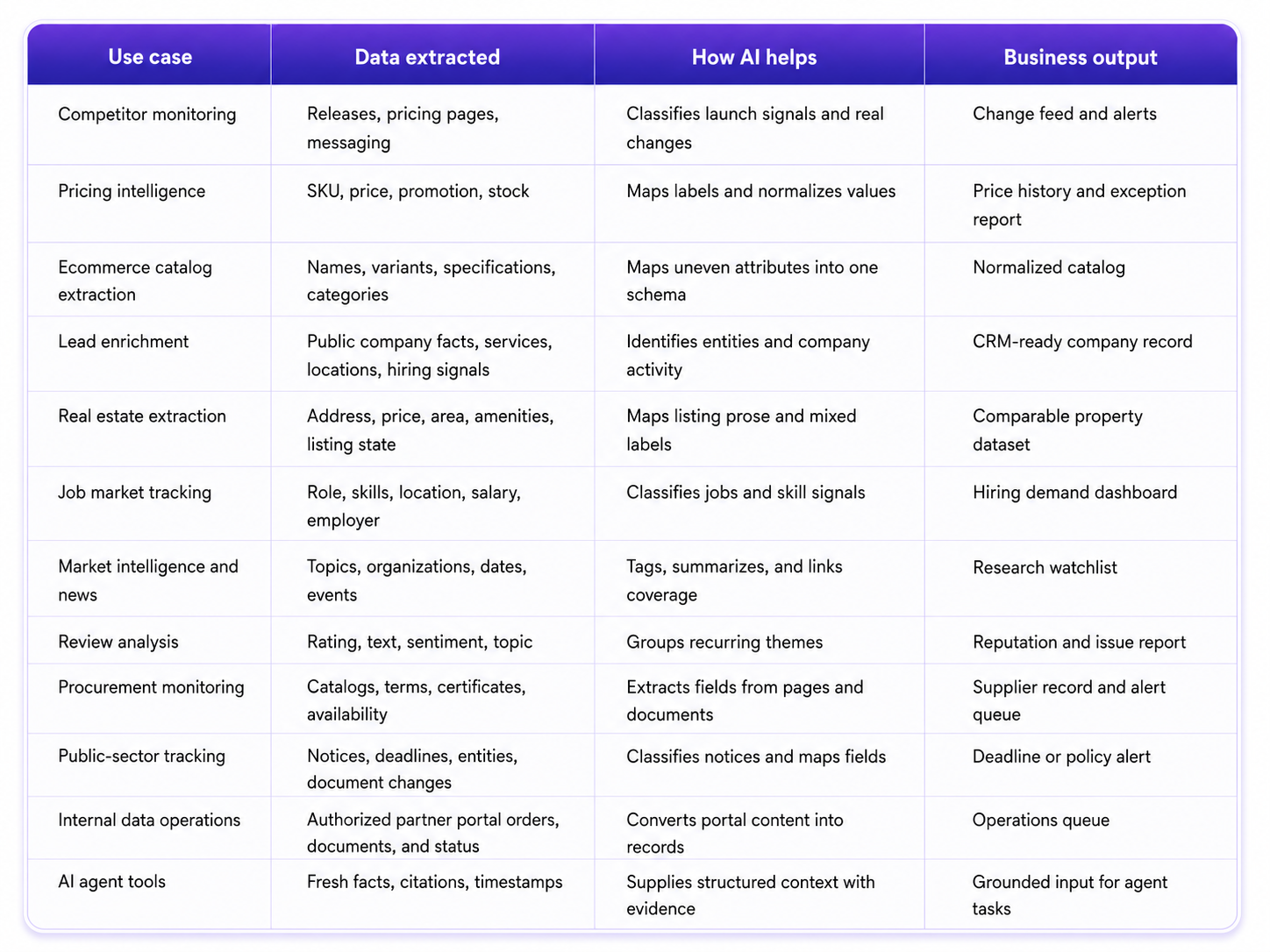
Lead enrichment and partner portals may involve personal or restricted data, which calls for stricter privacy, retention, and review rules.
AI scraping architecture for business systems
A business system often contains these parts:
- Crawler or browser layer: Fetches approved URLs and renders pages when needed.
- Queue and scheduler: Controls timing, retries, priorities, and job state.
- Rate and network controls: Apply source limits, backoff, and lawful routing. A proxy does not grant permission.
- Extraction and model services: Run selectors, parsers, OCR, classifiers, or language-model prompts.
- Validation service: Checks schemas, evidence, business rules, and confidence.
- Storage and search: Keep snapshots, structured records, history, and, when useful, a text index or vector database.
- Admin and review tools: Manage sources, schedules, schemas, failures, and uncertain records.
- API, alerts, reports, and logs: Send approved data to business software and record failures, versions, costs, and field errors.
A real build spans backend engineering, data governance, workflows, and product screens. A [Link to Web Application Development Service Page] can cover dashboards and review tools, while Python or Node.js workers run extraction jobs.
AI scraping tools vs custom AI scraping systems
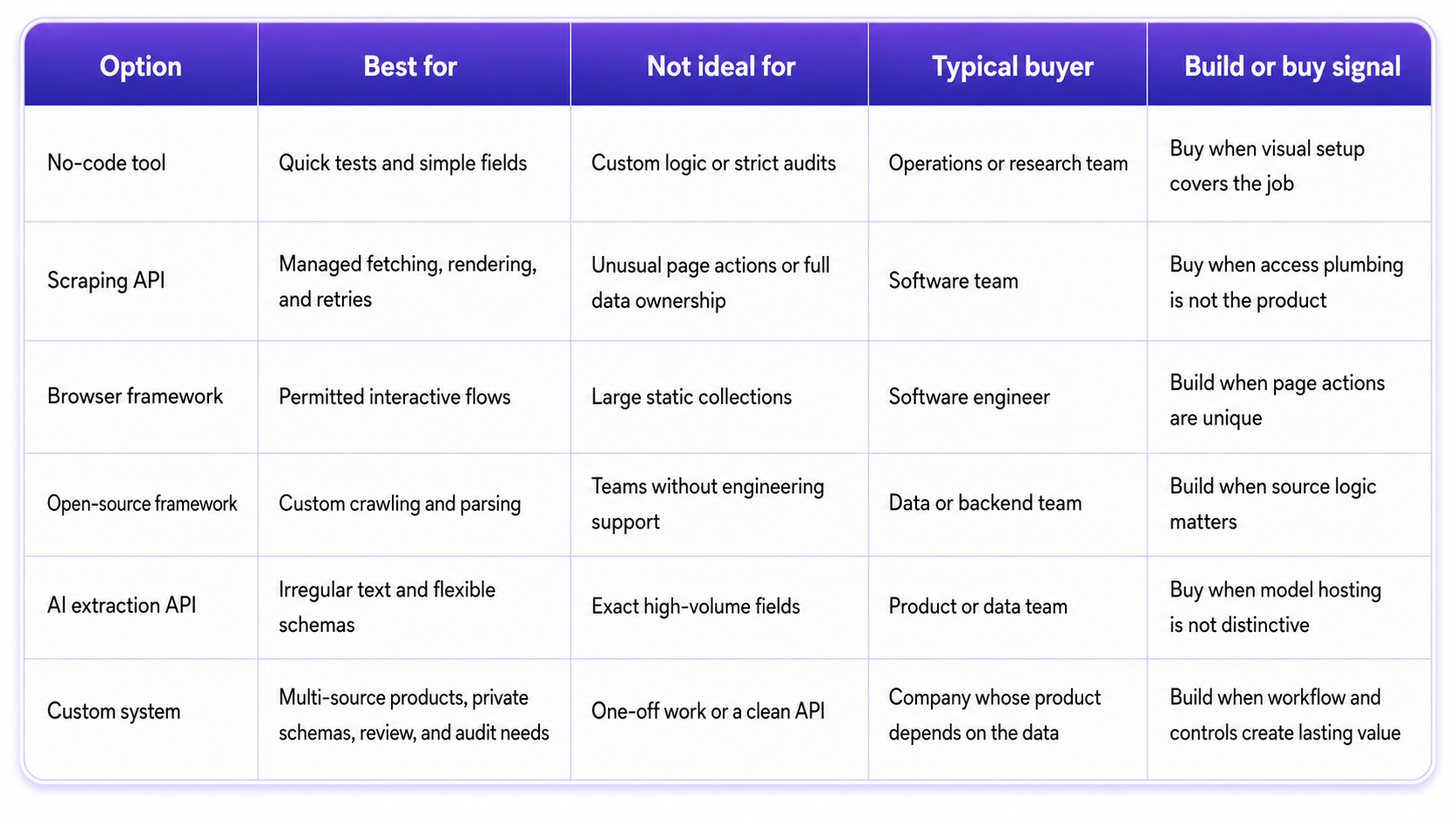
Browse AI covers no-code work. ScrapingBee, Firecrawl, and Zyte package APIs. Playwright and Selenium control browsers, Scrapy handles crawling, and Apify adds reusable crawlers and schedules.
Buy for a narrow source set and standard workflow. Build when the data shapes a customer product or needs private scoring, review, and tight system connections.
Legal, ethical, and privacy concerns
AI does not change the permission question. It changes how content is interpreted after access.
The robots.txt standard lets site owners publish crawler instructions. It is not an authorization system or security control. Responsible systems still read it, apply source policies, identify themselves where suitable, and avoid unnecessary load.
Website terms of service may set rules for automated access, reuse, accounts, and restricted areas. Contract rules vary by jurisdiction and facts. Teams should not bypass login controls, paywalls, technical blocks, or rate limits without clear permission.
Copyright needs a separate review. Facts and expressive content are not treated the same way, and copying, storing, displaying, or training on content can raise different questions. A license or direct data agreement may be safer for a high-value dataset.
Public personal data still carries privacy duties. Under GDPR and similar laws, teams may need a lawful basis, defined purpose, data minimization, retention limits, deletion handling, security, and support for data subject rights. Public availability is only one factor.
Teams should review legal, privacy, and contractual constraints before collecting or storing web data. This article is not legal advice.
Data quality and operational risks
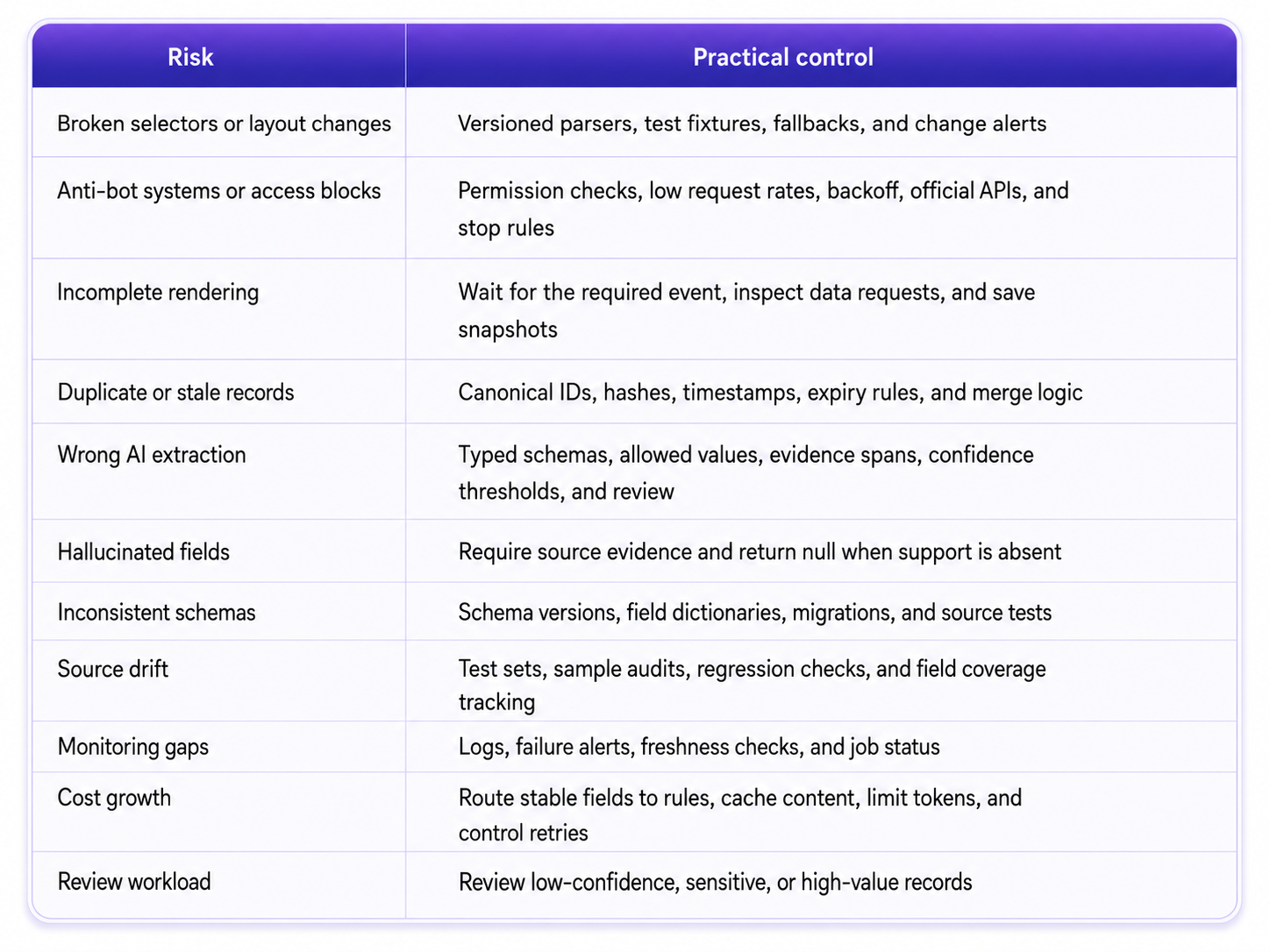
Snapshots and audit logs trace disputed records. Regression checks catch falling field coverage. Clear retention policies reduce privacy exposure and storage cost.
When AI scraping is not the right choice
AI scraping may be unnecessary when:
- A clean, licensed API supplies the required data.
- Stable HTML contains a small set of exact fields.
- Page volume makes model extraction too costly.
- Sensitive data lacks a clear lawful basis.
- The task requires exact extraction with no interpretation.
- A direct data partnership or licensed dataset is available.
- A one-time collection is small enough for manual review.
Start with the simplest method that meets the need. Add AI only where semantic interpretation or source variation justifies its cost and error risk.
A minimal AI scraping example
A sales team wants to monitor public company websites for new product launches.
- A crawler visits approved product, newsroom, and release pages.
- The system extracts visible text and saves a timestamped snapshot.
- A classifier checks for a new product signal.
- A language model maps product name, launch wording, date, and category to a fixed schema.
- Rules require a product name, source quote, valid date, and allowed category.
- The system deduplicates and stores the finding.
- A dashboard shows the change, and the sales team receives an alert with the source link.
The alert should include source evidence, and uncertain findings should enter a review queue.
30-minute evaluation checklist
Use this checklist before choosing a tool or build:
- What sources do we need?
- Are official APIs, feeds, exports, or licenses available?
- Do site terms and crawler instructions allow collection?
- Does the data include personal, copyrighted, paywalled, or access-controlled material?
- How often does it change?
- What accuracy does the business process require?
- Which fields must be exact, and which need semantic interpretation?
- Can selectors and rules handle the task, or is AI needed?
- Who reviews uncertain or sensitive outputs?
- Where will snapshots and records be stored?
- How will the team detect failures, stale records, and source drift?
- Which business system will use the data?
A yes to irregular content and a no to suitable APIs points toward AI-assisted extraction. Stable fields point toward rules first.
Quick answers
Can an LLM replace CSS selectors?
Not by default. Selectors are faster and more predictable on stable pages. Language models help when meaning matters or layouts differ.
Is AI scraping legal?
AI scraping is not automatically legal or illegal. The answer depends on the source, access method, website and account terms, copyright or database rights, privacy law, purpose, storage, reuse, and jurisdiction. Review the specific workflow before collecting or storing data.
Does AI scraping bypass anti-bot controls?
It should not be designed for that. Seek permitted access, prefer APIs, feeds, or data agreements, limit load, and stop when access controls reject the crawler unless you have explicit authorization to proceed.
Partnering with Lexogrine
Lexogrine is an AI agent development company and custom software development partner. We build end-to-end AI scraping and web data extraction systems from scratch, including crawler logic, AI extraction workflows, Python and Node.js backends, React dashboards and admin panels, React Native mobile apps, customer portals, APIs, and AWS or Google Cloud Platform hosting.