What is AI Product Discovery?
Artificial intelligence product discovery is the investigative process of validating an AI or machine learning concept before engineers commit to full-scale development. It involves deeply understanding user problems, auditing data availability, assessing privacy and compliance constraints, and measuring technical viability before production code is written. This phase helps reduce the risk of expensive engineering failures by exposing predictable issues early, such as poor data quality, unacceptable model error rates, hallucinations, high inference costs, latency constraints, security limitations, or weak user adoption. Discovery does not guarantee a successful deployment, but it gives teams a structured way to test assumptions before they become costly implementation decisions.
Why AI projects fail without discovery
Organizations rush to write code. They see a new generative text model and immediately try to build a custom application around it. This approach leads to disastrous financial outcomes. The Standish Group notes that most IT projects fail due to unclear requirements and a lack of user involvement. In the machine learning space, the failure rate is even higher. Gartner predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by AI-ready data.
McKinsey’s 2025 research reported that 78% of respondents’ organizations used AI in at least one business function, while 71% regularly used generative AI. Later McKinsey research indicated that AI adoption had risen further, but many organizations still had not achieved significant enterprise-level financial impact. The gap between laboratory success and user utility remains massive. A language model might write a perfect poem in a testing sandbox, but it will easily fail when tasked with securely parsing complex legal contracts in a live corporate environment. Traditional software planning falls short because it assumes the underlying technology works perfectly. Machine learning planning must assume the technology will hallucinate, fail, or cost too much to run.
Teams face several practical problems when they skip the planning stage:
- lack of data readiness: Engineers discover halfway through development that the required training information is unstructured, inaccessible, or legally restricted.
- misaligned model expectations: Leaders assume the tool will achieve 100% accuracy. The reality of probabilistic models dictates a margin of error that business units refuse to accept.
- high inference costs discovered too late: Companies build a functional tool but realize the API token fees make the business model unprofitable.
- poor user adoption due to UX friction: The interaction design causes friction. Users do not trust the automated outputs, leading to low usage metrics.
When teams ignore these factors, they accumulate massive technical debt. Fixing requirements defects costs 10 to 100 times more after release than during the initial planning phase.
The pillars of AI Product Discovery
A successful planning stage rests on four distinct pillars. These concepts adapt the standard product risk framework inspired by the Silicon Valley Product Group to fit the specific demands of machine learning.
Desirability
Teams often build automated tools simply because the technology exists, not because users requested it. Desirability measures whether the proposed application solves a genuine problem better than existing alternatives. If a user can accomplish a task faster with a simple keyword search, adding an expensive language model creates friction rather than value. Teams must validate demand through user interviews and prototype testing before committing engineering resources.
Viability
Viability examines the economic and legal constraints of the proposed system. A generative tool might be desirable to users, but it might violate strict data privacy laws. Viability covers the financial return. The business model must support the lifetime cost of the application, including computing power, database storage, and continuous model fine-tuning. If the cost to generate an answer exceeds the revenue gained from that answer, the project fails the viability test.
Feasibility
Feasibility tests the technical limits of current models. Teams must determine if available algorithms can process the specific domain logic required by the business. As an illustration, a medical diagnostic tool requires a level of factual precision that a general-purpose text model cannot guarantee without extensive guardrails. Furthermore, in such high-stake domains, feasibility must account for sector-specific regulations, such as the Medical Device Regulation (MDR) in the EU, which may impose stricter validation requirements than standard software. Feasibility checks reveal these limitations early, allowing teams to pivot toward more realistic architectures.
Data Readiness
This is the most demanding pillar. AI systems require access to sufficiently high-quality, legally usable, and well-governed information. The amount and structure required depend on the architecture: RAG, fine-tuning, classical ML, and agentic workflows have different data needs. If the organization's files are scattered across disconnected local drives, the system cannot retrieve accurate answers. Data readiness requires an audit of information freshness, completeness, and formatting. If the information is not ready, the project cannot proceed.
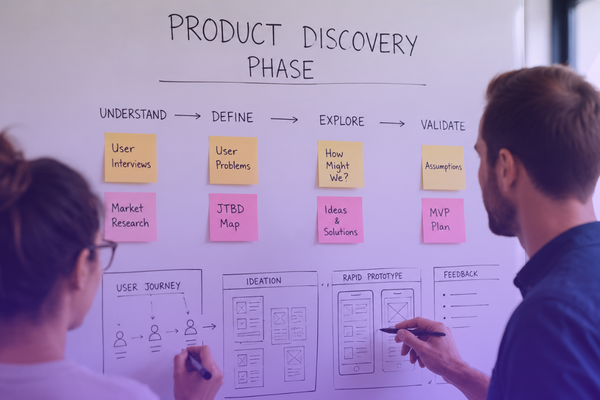
The AI Discovery Workflow
Running a structured discovery phase requires a sequential, evidence-based approach. The workflow moves a concept from a vague idea to a rigorously tested technical blueprint.
Stakeholder interviews and goal setting
The process begins with executive agreement. Product managers interview business leaders to establish specific performance targets. If the goal is customer service automation, the team sets measurable outcomes, such as reducing ticket volume by 30% without lowering customer satisfaction scores. This step prevents scope creep and ensures the engineering effort matches corporate objectives.
User research and AI-specific pain points
Researchers observe how users currently solve the problem. They document manual workflows and identify areas where automated intelligence could remove bottlenecks. Researchers use artificial intelligence tools to synthesize interview transcripts and identify recurring themes. The goal is to design an interaction flow that users will actually trust. If users fear the automated system will make mistakes, the interface must include human-in-the-loop review mechanisms.
Technical feasibility audit (Model selection, RAG vs. Fine-tuning)
Engineers step in to test different technical approaches. They evaluate whether the application requires a simple prompt interface, a RAG system, or a heavily fine-tuned proprietary model. They benchmark different language models against the specific business use case. This audit determines the processing requirements, the expected response delay, and the necessary cloud infrastructure.
Data audit and privacy assessment
Data scientists map all relevant information sources. They assess the quality of the historical records. If the application handles European citizen data, legal reviewers verify the architecture complies with the EU AI Act and GDPR restrictions. They verify whether personal data must be removed, anonymized, pseudonymized, minimized, contractually protected, or processed in a controlled environment before it reaches a model. Under GDPR, pseudonymized data can still remain personal data if re-identification is possible. Beyond privacy, this audit must now include an Intellectual Property (IP) review to ensure that the data used for grounding or fine-tuning is legally cleared for commercial use, mitigating future copyright litigation risks.
Prototyping (Low-fidelity vs. AI playgrounds)
Designers build low-fidelity mockups. They use specialized canvas tools and conversational playgrounds to simulate the final application. Users interact with these mockups. This allows the team to gather behavioral feedback without writing production-grade code. Generative interfaces can role-play as users to speed up the testing of edge cases.
Risk and compliance mapping
The final step involves mapping potential risks. The team identifies what happens if the model hallucinates or provides a dangerous instruction. They establish strict safety guardrails. This transition shifts the project from a technical proof of concept toward a true proof of value, designed to align the application's performance with economic objectives while establishing a defensible compliance posture under the EU AI Act’s risk classification framework.
Disclosure: We are not affiliated with the vendors listed in this article, unless explicitly stated.
Data and accuracy note (as of April 2026): This article is for general informational purposes only and does not constitute legal, medical, regulatory, security, or procurement advice. Vendor pricing, packaging, features, compliance statements, and review counts change over time. Figures referenced here were checked in April 2026 and should be verified on official vendor pages during evaluation. For PHI/PII workflows, confirm contract terms (including any BAA), product scope, retention settings, and security controls with your legal, privacy, and security teams before piloting.
How technical feasibility works in discovery
Technical scoping separates realistic projects from impossible dreams. During this stage, engineers do not build the entire application. They run targeted experiments to prove the main mechanics will function reliably in a production environment.
Here is why this matters. A standard text generation model might answer a general knowledge question in one second. When that same model must search through a massive proprietary vector database, rank the results, and synthesize a legally compliant response, the processing time can spike dramatically. Teams must benchmark model performance early. They define 'Acceptable Performance Thresholds' (accuracy, latency, cost, and hallucination rate) based on exact business requirements. Defining these thresholds early prevents 'scope creep' where teams chase an impossible 100% accuracy rate. If an application requires a sub-second response to remain usable, but the chosen architecture takes four seconds, the concept fails the feasibility test.
Engineers hunt for identifying potential "hallucination" risks in the specific domain. Every industry has unique terminology. A financial model might misinterpret a standard banking acronym, leading to a catastrophic automated trading decision. To prevent this, teams build a rigorous evaluation dataset. This dataset contains hundreds of complex questions paired with verified, human-written answers. Engineers run the language model against this dataset to measure its true error rate. If the error rate exceeds the accepted performance target, the team must adjust the architecture or abandon the feature.
Testing the data pipeline logic is equally demanding. Engineers evaluate different vector database options for search accuracy. They test how the system chunks large documents into readable segments. They compare the performance of commercial APIs against self-hosted open-source models. This comparison dictates the entire hosting strategy, informing whether the company relies on external vendors or builds internal infrastructure.
Data at the center of discovery
Data is the absolute foundation of machine learning. Without clean, accessible information, even the most advanced neural network becomes useless. The discovery phase places data auditing at the center of all technical planning.
Teams begin by auditing what a team needs to audit (quality, volume, structure). They inventory all necessary databases and document repositories. They look for missing records, outdated files, and contradictory instructions. Identifying data gaps is mandatory. If an organization wants to build an automated human resources assistant, but the employee handbook contradicts the internal benefits wiki, the automated assistant will provide confusing answers. Teams must identify these data gaps and force the business units to resolve them before development starts.
Privacy and security constraints heavily dictate the architecture. The EU AI Act and GDPR strictly govern how companies process personal information. If an application requires access to sensitive medical records or financial histories, the team must evaluate whether and how cloud-based AI services can process the data lawfully and securely. They must design a masking layer that anonymizes the records before ingestion. Alternatively, they must select a self-hosted model that keeps all processing within the company's secure internal network.
This reality means that how data availability dictates the AI architecture is an absolute rule. If the required information is locked inside a legacy system without modern API access, the team must build custom extraction pipelines. The cost of building those pipelines often exceeds the cost of building the machine learning model itself. Discovering these hidden data dependencies early saves companies from funding projects that are structurally impossible to complete.
Discovery outcomes for real AI products
A well-executed discovery process produces tangible, highly valuable documents. These documents guide the engineering teams and protect the executive sponsors from unexpected budget overruns.
Next steps become entirely predictable. The team delivers a validated product backlog. This backlog lists every required feature, ranked by business priority and technical difficulty. Engineers know exactly what to build first to deliver maximum value.
The process yields a clear technical architecture (e.g., choice of LLM and Vector DB). This document specifies the exact language model to use. It names the chosen vector database. It outlines the retrieval-based generation strategy. It defines the cloud infrastructure required to host the system, detailing the necessary computing instances and storage volumes.
Financial predictability is a major outcome. The discovery phase generates a preliminary cost estimate (API costs, infrastructure). This estimate covers the engineering labor required to build the initial release. More importantly, it forecasts the ongoing operational expenses. It calculates the expected API token costs based on projected user volume. It projects the monthly cloud hosting fees. This allows the finance department to run a true cost benefit analysis before authorizing the full budget.
Finally, the team produces a roadmap for the MVP. Because the requirements are strict and the technical hurdles are known, the project managers can accurately predict delivery dates. The gap between expectation and reality narrows, because major assumptions have been tested before full-scale engineering begins.
Trademarks and references: Product and company names may be trademarks of their respective owners. References are for identification only and do not imply endorsement.
Commercial note: This article includes a “Partner with Lexogrine” section describing Lexogrine services. The product shortlist and evaluation guidance are editorial and based on publicly available vendor documentation and third-party review platforms.
Benefits and tradeoffs
Business leaders often resist spending weeks on research. They want to see working software immediately. Yet, the tradeoffs heavily favor a structured planning phase.
Lower long-term development costs represent the most immediate benefit. Fixing a structural defect after a product launches costs exponentially more than catching it during the design phase. If engineers build an entire data pipeline based on a flawed assumption about database access, they must tear down the entire system and start over. Discovery prevents this waste.
Faster time to market for the right product is another major advantage. While discovery requires an upfront time investment, it accelerates the actual coding phase. Engineers do not waste weeks debating which model to use or waiting for legal approvals. The requirements are clear. They write code faster, and the resulting application perfectly matches user needs.
Higher stakeholder confidence skyrockets. When a project leader presents a technical blueprint backed by rigorous data audits and user testing, the board of directors feels secure authorizing the budget. The project shifts from a speculative gamble into a predictable engineering exercise.
Time spent upfront vs. potential "sunk cost" if a project is killed early (which is a win) is the final consideration. This is the most counterintuitive benefit. Discovering that a project is unviable during the planning phase is a massive victory. Spending a small amount of money to realize an idea will not work saves the company from spending millions of dollars building a doomed application.
Security, ethics, and governance in discovery
Deploying machine learning introduces severe risks regarding bias, fairness, and legal liability. A proper scoping phase addresses these threats systematically.
Identifying bias early requires deep evaluation. If a company builds an automated resume screening tool using historical hiring data, the model may learn or amplify past discriminatory practices. During discovery, data scientists examine the training sets for demographic imbalances. They run fairness evaluations to guarantee the model outputs do not disadvantage protected groups.
GDPR/regulatory alignment for AI is indispensable. Frameworks like the EU AI Act classify applications based on their risk level. An application that makes decisions about human employment or medical treatment faces intense legal scrutiny. The planning phase maps these regulatory requirements, ensuring the company builds the necessary compliance reporting tools directly into the software architecture.
Setting up guardrails before writing production code protects the brand. Teams must define strict operational boundaries. They decide how the model handles toxic prompts. They define what topics the model is explicitly forbidden from discussing. They assign clear human ownership for risk decisions. When the application eventually launches, it operates within a secure, legally defensible framework.
Should you run a discovery phase now?
Deciding whether to pause and run a full planning phase depends on the difficulty of the proposed application. Business leaders need a practical decision framework to guide their investments.
Here is why. When discovery is mandatory (complex domains, new tech) becomes clear upon review. If the application handles medical advice, financial transactions, or legal document generation, the tolerance for error is zero. The team must thoroughly validate the architecture. Discovery is also required when adding untested, brand-new technologies. If the organization wants to deploy autonomous agents that can execute database commands independently, the security risks demand an exhaustive audit.
Conversely, when a company might skip it (very simple wrappers, internal testing) is also easy to identify. If a small marketing team wants to build a simple interface over a public API to help draft weekly newsletters, the financial and technical risks are minimal. The team can simply build the tool and test it live.
What teams should evaluate:
- data complexity: Are the necessary files structured and clean, or are they scattered across legacy systems?
- model uncertainty: Can a standard, off-the-shelf API solve the problem, or does the task require custom fine-tuning?
- budget constraints: Will the expected API usage costs remain low, or could high token volume threaten the project's financial viability?
- user feedback availability: Can the team easily test prototypes with real users, or is the target audience difficult to reach?
Checklist:
If a project leader answers "Yes" to any of the following questions, a dedicated discovery phase is required before engineering begins:
- Does the application process sensitive, personal, or regulated information?
- Will the system make automated decisions that impact employee workflows or customer finances?
- Does the project require merging data from more than three separate internal databases?
- Is the expected lifetime cost of the application projected to exceed the initial development budget?
- Would a hallucinated or factually incorrect output cause reputational damage to the brand?
- Is there uncertainty regarding the copyright status or licensing of the primary data sources intended for the model?
Hypothetical discovery scenario: why data readiness comes before automation
The following scenario is hypothetical, but it reflects a common pattern in AI discovery work.
A logistics company wants an AI support bot to answer driver questions about delivery routes and HR policies. The executive team expects the engineering department to build and launch the bot within four weeks. Before development begins, the engineers recommend a short discovery phase to test whether the data and architecture can support the use case.
Discovery reveals that the core knowledge sources are not ready for automation. Routing guidelines are stored in an outdated wiki. HR policies exist as scanned PDF files and inconsistent documents across multiple folders. Early tests show that the model gives contradictory answers because the source material itself is incomplete, outdated, or conflicting.
Instead of launching an unreliable assistant, the team reframes the first milestone as a knowledge base cleanup project. They centralize the relevant documents, remove outdated guidance, digitize scanned files, define ownership for policy updates, and prepare the content for retrieval.
Once the knowledge base is reliable, the company can revisit the assistant with a stronger foundation. The discovery phase does not “prove” that the bot will succeed, but it identifies the real bottleneck before the team spends the full engineering budget on an unreliable system.
Partnering with Lexogrine
Building custom artificial intelligence systems requires specialized engineering and rigorous planning. Lexogrine helps companies turn early AI ideas into usable digital products.
Our team can support both the discovery phase and the implementation that follows, from AI-powered workflows and internal tools to web platforms, mobile apps, admin panels, and customer portals. We work with technologies such as React, React Native, Node.js, AWS, and modern AI tooling to build products that are practical, secure, and ready for real users.